

什么是ABBYY FlexiCapture?
ABBYY FlexiCapture不仅仅是一个智能数据捕获和提取解决方案,它将最顶尖的人工智能(AI)、自然语言处理(NLP)、机器学习(ML)和高级识别功能整合到一个企业级文档自动化平台中,能够转换业务文档中的所有数据。
FlexiCapture让企业掌握文档处理自动化的能力,使全球组织能够实现更快的引导、无接触的处理、更低的成本和更清晰的流程。探索FlexiCapture规范,包括格式和语言、服务器、工作站和虚拟环境。

可在云端、内部部署或作为软件开发工具包提供
从明天开始,将解决方案部署到对您的关键业务领域。
倍受全球 10,000多家顶尖公司 的信赖




倍受全球 10,000多家顶尖公司 的信赖
企业自动化从这里开始
企业文档自动化在一个专门构建的综合人工智能平台上获取、处理、验证正确的数据,并将数据交付到关键流程中。
直接处理业务关键文档
通过任何渠道、任何格式输入的文档中的内容都将实现自动提取、理解和传递,从而消除手动处理的摩擦。
平稳的交易、明智的决策和快速的行动
利用客户提供的数据加速交易,做出更明智的决策,并为客户提供快速、准确的响应。
控制、可预测性和合规性
获取全链条的托管报告和管理,以便对结果进行微调,同时确保端到端符合您的流程和安全模型。
智能数据提取
您如今利用自然语言处理(NLP)技术可以自动识别和提取非结构化、复杂文档,以及结构化和半结构化文档中的数据。这有助于加速交易,同时显著降低运营成本和错误。
数据验证和控制
根据业务规则和要求,对关键数据字段、上下文和实体进行识别、验证和自动处理。此系统的训练十分简单,并将利用持续机器学习实现持续改进和成本控制。
云可用性
依靠FlexiCapture,您可以自由选择部署选项。FlexiCapture可以在您的关键业务领域运行。FlexiCapture的配置可以部署到本地或云,并且与两者兼容。
ABBYY通过流程标准化帮助DHL降低交易成本%
“我认为,当像DHL一样的公司需要尽量减少人为互动时,ABBYY确实能够帮助他们交付服务。”
运用Flexicapture实现文档自动化——工作原理
ABBYY FlexiCapture是一个高度准确、可扩展的文档工作流平台。它可以智能地捕获、分类关键数据,并将数据从非结构化和结构化文档传输到正确的流程、工作流或决策引擎。
数据输入
ABBYY FlexiCapture能在一个流程中自动处理文件和扫描仪中的各类文档,包括办公室文档和图像格式、电子邮件附件和邮件正文。
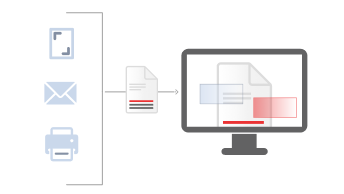
分类和识别
基于神经网络的自动文档分类技术能够按类型(驾驶执照、银行对账单、纳税单、合同、发票等),以及按文本内容和图像模式的自定义子类别(例如,供应商A的发票、供应商B的发票),对文档进行排序。 ABBYY FlexiCapture能够快速学习,发挥自动分类器的作用。 文档图像将被汇集成多页文档集。
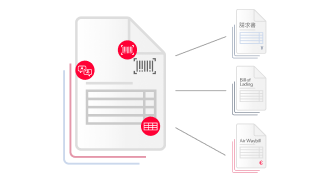
数据提取和验证
文档内容和数据会自动提取和验证。FlexiCapture提供高度准确的光学字符识别/智能字符识别/光学标记识别和条形码识别功能。自动验证包括与数据库的比较以及与内置验证规则的一致性。 验证站允许检查提取的字段是否与原始文档的字段匹配。
与顶级机器人流程自动化和工作流自动化系统实现紧密集成




云可用性
开发选项
FlexiCapture可以在您的业务关键领域运行,期配置可以部署到本地或云端,并与两者兼容。ABBYY FlexiCapture Cloud的服务在Microsoft Azure上运行,利用其安全性和数据保护,并为您提供地理区域选择。
安全性
ABBYY FlexiCapture Cloud具有与基础设施和平台层相关的本机安全功能。此产品已通过SOC2 1型认证,其设计合理,符合TSP第100节中规定的安全和保密原则;符合《2017年信托服务安全性、可用性、处理完整性、保密性和隐私标准》(AICPA);符合《信托服务标准》。审计报告由德国普华永道会计师事务所发布。
集成和API
ABBYY FlexiCapture Cloud REST API可轻松实现与系统的紧密集成。REST API允许外部系统上传文档和接收提取结果,通过提供有关结果质量的反馈来训练FlexiCapture,以及开发自定义验证。
领先技术
多级文档分类
运用最新的机器学习方法,通过自动训练的基于人工智能的分类器,使理解、分离和路由文档的任务实现自动化。无论是处理和分类结构化表格、半结构化文档(如发票、税务表格、索赔或入职文档),还是完全非结构化文档(例如信函和合同),FlexiCapture都可以帮助您在加快流程的同时降低文档处理成本,无需人工分拣和贴标签。
自然语言处理(NLP)
附带自然语言处理(NLP)功能的最新版FlexiCapture扩展了其捕获功能,现已涵盖非结构化文档,如合同、租约、文章、协议和电子邮件。依靠自然语言处理技术,您可以自动化更多需要手动数据输入的业务流程,并在业务应用程序中快速提供重要的文档数据,从而节省时间、金钱和劳动力。通过用户反馈对自然语言处理模型进行额外训练,从而使数据提取的质量不断提高,减少验证成本和时间。
持续学习
新的自动学习功能有助于加快您的生产速度,并显著降低持续系统支持和维护成本。\该技术可帮助用户训练系统处理灵活或不规则的文档布局,同时管理员保留编辑、微调或放弃自动学习结果的完全控制权。该系统利用ABBYY先进的机器学习和自然语言处理技术,根据用户的反馈不断学习和改进。
分类技术
输入的通信可以按形式和内容进行分类,以优化组织的信息驱动流程。分类技术使用深度学习卷积神经网络来检测包括图像在内的每一种传入文档类型,并根据外观或模式对文档进行分类;以及基于统计和语义文本分析进行文本分类。ABBYY FlexiCapture允许用户单独使用其中任意一种技术,或者将两种技术结合使用,以缩短响应时间,确保及时决策。
图像增强和处理
图像增强功能可自动改进被移动设备捕获的图像,并优化图像。此功能对处理具有复杂背景的文档(如成绩单、身份证明文件和运输表格)而言也是必不可少的,而且还能够自动优化图像以进行后续处理,或者在图像质量较差时提供即时反馈。自动裁剪、背景白化、图像质量评估以及为不同图像源创建自定义增强配置文件等功能可帮助你处理所有文档,无论其质量或来源如何。
手写智能字符识别
FlexiCapture利用其先进的智能字符识别(ICR)技术识别手写数据,提取字段、标记中的手写数据,或票据、收据、医疗表格、处方、申请、索赔、发票和其他财务或运输文档中的全文。内置的人工智能技术有助于加快文档处理并提高识别水平。
额外信息和产品规格
智能文档处理(IDP)——常见问题
问 : 智能文档处理的工作原理是什么?
答 : 智能文档处理应用人工智能和机器学习技术,能够像人一样读取和处理文档中的内容。虽然传入的业务数据来自各种来源——电子邮件和附件、数字文档(如PDF)、传真、纸质扫描图像等,但IDP即可节省时间、减少错误,又能确保快速、准确地自动处理来自这些文档源(结构化、半结构化和非结构化)的数据。
问 : 智能文档处理与OCR是一回事吗?
答 : 不是。虽然IDP确实包含了OCR,但它的功能更广泛。IDP扩展了光学字符识别(OCR)和数据捕获技术,并使用机器学习、自然语言处理和其他先进技术将“智能”纳入其中,为内容处理增加了更多的专家技能和决策能力。
问 : 智能文档处理是RPA(机器人流程自动化)吗?
答 : 不,IDP不是RPA。虽然RPA可以在基于数据运行的已定义业务流程中自动执行重复任务,但RPA无法理解上下文内容并做出熟练决策。RPA可以通过ABBYY Vantage等智能文档处理技术进行增强,以获得智能处理文档内容所需的能力。在此了解更多信息。