ABBYY Screenshot Reader 是一款易于使用的智能型应用程序,它可以从屏幕上的任何区域抓取图像和文本这两类屏幕截图。
不仅仅是屏幕截屏工具
您可以在打开文件的文本,图片,文件菜单,网页,简报,PDF文件里只需几个点击您就可以创建自己的快照截屏。Screenshot Reader创建的图像,您可以轻松地从您的剪贴板剪切并粘贴到Microsoft PowerPoint,Word,Excel或图形文件。它已经不仅仅是一个简单的截屏工具,您可以使用Screenshot Reader在图像、flash文件、PDF和其他基于图像的文件中选中区域,进行识别并转换成真正的可编辑文本,或将其插入到另一个文件。
图像截屏的捕获

转换成可编辑的文本和表格

截图
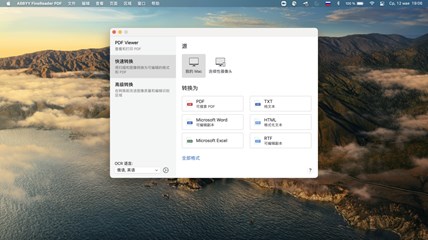
主要特点

捕捉两种类型的屏幕截屏-图片和文本
使用ABBYY Screenshot Reader,您可以决定是否对桌面应用,Web站点,演讲,或一个文档区域采取传统的图片截图方式,或者您可以把图形文件中的文本制成可编辑的文本和创建'文本截图'。

图片截屏
轻松创建和保存图像截图,您可以与朋友分享或在演示,制作培训材料和各种其他文件中使用。先进的计时截屏功能让您可以延迟5秒才截图,这样让您有更多的时间来准备屏幕- 例如,为一个软件来制作文档是,您可以按照菜单来打开文件。

文本截屏
如果您想抓住从一个图像文件,网站,简报,或PDF的一些文本,您可以将其迅速转化为真正的可编辑的文本,您也可以直接粘贴到一个开放的应用程序,编辑或保存为Microsoft ® Word或Excel ®文件。Screenshot Reader可以将截屏图片转化成文字。

方便使用的应用工具
该程序的主要屏幕可以选择一个区域来截屏,同时设置一个输出格式。Screenshot reader可以设置启动时自动启动,随手掌控。

多样的保存格式
ABBYY Screenshot Reader 可以让您将图片保存成JPEG, Bitmap 或者PNG 格式。文本截屏可以被保存成.RTF, .TXT, .DOC or .XLS格式
想试试屏幕截图识别工具吗?
Screenshot Reader → 技术参数
技术参数
系统要求
操作系统
- Microsoft® Windows® 10 / 8.1 / 8 / 7
- Microsoft Windows Server® 2016 / 2012 / 2012 R2 / 2008 R2
- 为使用本地化语言界面,系统必须具备相应的语言支持。
硬件
- 1 GHz或更快的PC
- 1024 MB RAM
- 硬盘空间:600MB安装空间,还700MB空间为最佳程序操作
- 视频卡1024x768或更高分辨率
文档保存格式
DOC
Microsoft Word 97-2003 Document
RTF
Rich Text Format
XLS
Microsoft Excel 97-2003 Document
CSV
Microsoft Office Excel Comma-Separated Values File
TXT
Text document
ODT
OpenOffice.org Writer format
JPEG
灰度和彩色
PNG
黑白,灰度和彩色
BMP
黑白,灰度和彩色
注意: 为了能把捕捉的文字直接发到 Microsoft Word 或者 Microsoft Excel,你必须在计算机上安装相应的应用程序
用户界面语言
保加利亚语
简体中文
繁体中文
捷克语
丹麦语
荷兰语
英语

爱沙尼亚语
德语
希腊语
匈牙利语
意大利语
日语
朝鲜语
波兰语
葡萄牙语(巴西)
Russian
斯洛伐克语
西班牙语
瑞典语
土耳其语
乌克兰语
越南语
识别语言
ABBYY Screenshot Reader 支持180多*种OCR语言的所有的组合和~40种语言包括字典支持(标记 ×):
- Abkhaz
- Adyghe
- Afrikaans
- Agul
- Albanian
- Altaic
- Armenian (Eastern) ×
- Armenian (Grabar) ×
- Armenian (Western) ×
- Avar
- Aymara
- Azeri (Cyrillic)
- Azeri (Latin) ×
- Bashkir ×
- Basic
- Basque
- Belarusian
- Bemba
- Blackfoot
- Breton
- Bugotu
- Bulgarian ×
- Buryat
- C/C++
- Catalan ×
- Cebuano
- Chamorro
- Chechen
- Chinese Simplified
- Chinese Traditional
- Chukchee
- Chuvash
- COBOL
- Corsican
- Crimean Tatar
- Croatian ×
- Crow
- Czech ×
- Dakota
- Danish ×
- Dargwa
- Dungan
- Dutch ×
- Dutch (Belgian) ×
- English ×
- Eskimo (Cyrillic)
- Eskimo (Latin)
- Esperanto
- Estonian ×
- Even
- Evenki
- Faroese
- Fijian
- Finnish ×
- Fortran
- French ×
- Frisian
- Friulian
- Gagauz
- Galician
- Ganda
- German (Luxembourg)
- German (new spelling) ×
- German ×
- Greek ×
- Guarani
- Hani
- Hausa
- Hawaiian
- Hebrew ×
- Hungarian ×
- Icelandic
- Ido
- Indonesian ×
- Ingush
- Interlingua
- Irish
- Italian ×
- Japanese ×
- Java
- Jingpo
- Kabardian
- Kalmyk
- Karachay-Balkar
- Karakalpak
- Kasub
- Kawa
- Kazakh
- Khakass
- Khanty
- Kikuyu
- Kirghiz
- Kongo
- Korean ×
- Korean (Hangul) ×
- Koryak
- Kpelle
- Kumyk
- Kurdish
- Lak
- Latin ×
- Latvian ×
- Lezgi
- Lithuanian ×
- Luba
- Macedonian
- Malagasy
- Malay
- Malinke
- Maltese
- Mansi
- Maori
- Mari
- Maya
- Miao
- Minangkabau
- Mohawk
- Romanian (Moldova)
- Mongol
- Mordvin
- Nahuatl
- Nenets
- Nivkh
- Nogay
- Norwegian (Bokmal) ×
- Norwegian (Nynorsk) ×
- Nyanja
- Occidental
- Occitan
- Ojibway
- Ossetian
- Papiamento
- Pascal
- Polish ×
- Portuguese ×
- Portuguese (Brazil) ×
- Quechua (Bolivia)
- Rhaeto-Romance
- Romanian ×
- Romany
- Rundi
- Russian ×
- Russian (old spelling) ×
- Rwanda
- Sami (Lappish)
- Samoan
- Scottish Gaelic
- Selkup
- Serbian (Cyrillic, Latin)
- Shona
- Simple chemical formulas
- Slovak ×
- Slovenian ×
- Somali
- Sorbian
- Sotho
- Spanish ×
- Sunda
- Swahili
- Swazi
- Swedish ×
- Tabasaran
- Tagalog
- Tahitian
- Tajik
- Tatar ×
- Thai ×
- Tok Pisin
- Tongan
- Tswana
- Tun
- Turkish ×
- Turkmen (Cyrillic)
- Turkmen (Latin)
- Tuvinian
- Udmurt
- Uighur (Cyrillic, Latin)
- Ukrainian ×
- Uzbek (Cyrillic, Latin)
- Vietnamese ×
- Welsh
- Wolof
- Xhosa
- Yakut
- Yiddish
- Zapotec
- Zulu





